deep learning
gaussian process
pytorch
pyro
bayesian
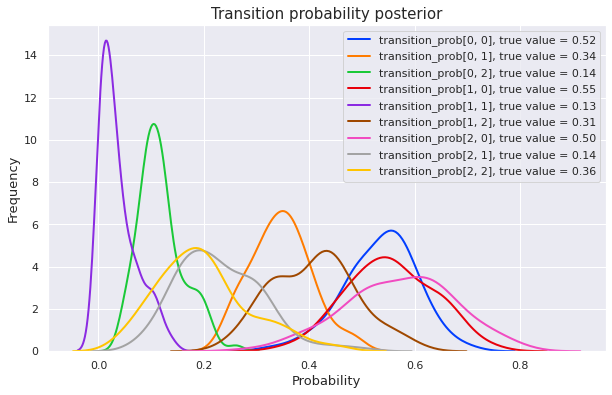
hidden markov model
pytorch
pyro
algorithm
project euler
python
numba
deep learning
seq2seq
pytorch
torchtext
math
complex analysis
jupyter
katex
algorithm
project euler
python
numba
No matching items
Back to top