import argparse
import os
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
from torch.nn.utils import clip_grad_norm
import torchtext.data as dataHow to build a Grapheme-to-Phoneme (G2P) model using PyTorch
deep learning
seq2seq
pytorch
torchtext
introduction
Grapheme-to-Phoneme (G2P) model is one of the core components of a typical Text-to-Speech (TTS) system, e.g. WaveNet and Deep Voice. In this notebook, we will try to replicate the Encoder-decoder LSTM model from the paper https://arxiv.org/abs/1506.00196.
Throughout this tutorial, we will learn how to: + Implement a sequence-to-sequence (seq2seq) model + Implement global attention into seq2seq model + Use beam-search decoder + Use Levenshtein distance to compute phoneme-error-rate (PER) + Use torchtext package
setup
First, we will import necessary modules. You can install PyTorch as suggested in its main page. To install torchtext, simply call > pip install git+https://github.com/pytorch/text.git
Due to this bug, it is important to update your torchtext to the lastest version (using the above installing command is enough).
argparse is a default python module which is used for command-line script parsing. To run this notebook as a python script, simply comment out all the markdown cell and change the following code cell to the real argparse code.
parser = {
'data_path': '../data/cmudict/',
'epochs': 50,
'batch_size': 100,
'max_len': 20, # max length of grapheme/phoneme sequences
'beam_size': 3, # size of beam for beam-search
'd_embed': 500, # embedding dimension
'd_hidden': 500, # hidden dimension
'attention': True, # use attention or not
'log_every': 100, # number of iterations to log and validate training
'lr': 0.007, # initial learning rate
'lr_decay': 0.5, # decay lr when not observing improvement in val_loss
'lr_min': 1e-5, # stop when lr is too low
'n_bad_loss': 5, # number of bad val_loss before decaying
'clip': 2.3, # clip gradient, to avoid exploding gradient
'cuda': True, # using gpu or not
'seed': 5, # initial seed
'intermediate_path': '../intermediate/g2p/', # path to save models
}
args = argparse.Namespace(**parser)Next, we need to download the data. We will use the free CMUdict dataset. The seed 5 is used to generate random numbers for the purpose of replicating the result. However, we still observe distinct scores for different runs of the notebook.
args.cuda = args.cuda and torch.cuda.is_available()
if not os.path.isdir(args.intermediate_path):
os.makedirs(args.intermediate_path)
if not os.path.isdir(args.data_path):
URL = "https://github.com/cmusphinx/cmudict/archive/master.zip"
!wget $URL -O ../data/cmudict.zip
!unzip ../data/cmudict.zip -d ../data/
!mv ../data/cmudict-master $args.data_path
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)model
Now, it is time to define our model. The following figure (taken from the paper) is a two layer Encoder-Decoder LSTM model (which is a variant of Sequence-to-Sequence model). To understand how LSTM works, we can look at the excellent blog post http://colah.github.io/posts/2015-08-Understanding-LSTMs/. Each rectangle in the figure will be an LSTMCell in our code.

Before looking into the code, we need to review some PyTorch modules and functions: + nn.Embedding: a lookup table to convert indices to vectors. Theoretically, it does one-hot encoding followed by a fully connected layer (with no bias). + nn.Linear: nothing but a fully connected layer. + nn.LSTMCell: a long short-term memory cell, which is mentioned above. + size: get the size of tensor. + unsqueeze: create a new dimension (with size 1) for a tensor. + squeeze: drop a (size 1) dimension of a tensor. + chunk: split a tensor along a dimension into smaller-size tensors. There is also the function split which help us obtain the same effect. + stack: concatenate a list of tensors along a new dimension. If we want to concatenate a long a “known” dimension, then we can use cat function. + bmm: batch matrix multiplication. + index_select: select values of a tensor by providing indices. + F.softmax, F.tanh: non-linear activation functions.
PyTorch’s implementation of the encoder is quite straight forward. If you are not familiar with PyTorch, we recommend you to look at the official tutorials. It is noted that the dimension for input tensor x_seq is seq_len x batch_size. After embedding, we get a tensor of size seq_len x batch_size x vector_dim, not batch_size x seq_len x vector_dim. For us, this order of dimensions is useful for getting subsequence tensor, or an element of the sequence (for examples, to get the first element of the sequence x_seq, we just take x_seq[0]). Note that this is also the default order of input tensor for any recurrent module in PyTorch.
class Encoder(nn.Module):
def __init__(self, vocab_size, d_embed, d_hidden):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_embed)
self.lstm = nn.LSTMCell(d_embed, d_hidden)
self.d_hidden = d_hidden
def forward(self, x_seq, cuda=False):
o = []
e_seq = self.embedding(x_seq) # seq x batch x dim
tt = torch.cuda if cuda else torch # use cuda tensor or not
# create initial hidden state and initial cell state
h = Variable(tt.FloatTensor(e_seq.size(1), self.d_hidden).zero_())
c = Variable(tt.FloatTensor(e_seq.size(1), self.d_hidden).zero_())
for e in e_seq.chunk(e_seq.size(0), 0):
e = e.squeeze(0)
h, c = self.lstm(e, (h, c))
o.append(h)
return torch.stack(o, 0), h, cNext, we want to implement the decoder with attention mechanism. The article http://distill.pub/2016/augmented-rnns/ explains very well the idea behind the notion “attention”. Here we use dot global attention from the paper https://arxiv.org/abs/1508.04025. (The following figure is taken from this blog.)
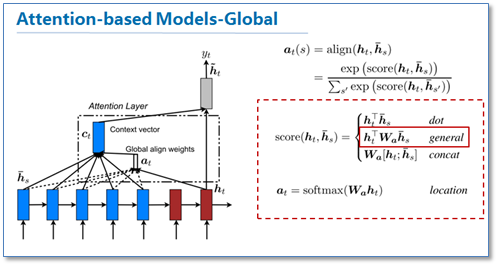
# Based on https://github.com/OpenNMT/OpenNMT-py
class Attention(nn.Module):
"""Dot global attention from https://arxiv.org/abs/1508.04025"""
def __init__(self, dim):
super(Attention, self).__init__()
self.linear = nn.Linear(dim*2, dim, bias=False)
def forward(self, x, context=None):
if context is None:
return x
assert x.size(0) == context.size(0) # x: batch x dim
assert x.size(1) == context.size(2) # context: batch x seq x dim
attn = F.softmax(context.bmm(x.unsqueeze(2)).squeeze(2))
weighted_context = attn.unsqueeze(1).bmm(context).squeeze(1)
o = self.linear(torch.cat((x, weighted_context), 1))
return F.tanh(o)Note that if we do not want to add attention to the decoder, then simply set the args.attention to False. In our experiment, adding attention gave us worse result.
class Decoder(nn.Module):
def __init__(self, vocab_size, d_embed, d_hidden):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_embed)
self.lstm = nn.LSTMCell(d_embed, d_hidden)
self.attn = Attention(d_hidden)
self.linear = nn.Linear(d_hidden, vocab_size)
def forward(self, x_seq, h, c, context=None):
o = []
e_seq = self.embedding(x_seq)
for e in e_seq.chunk(e_seq.size(0), 0):
e = e.squeeze(0)
h, c = self.lstm(e, (h, c))
o.append(self.attn(h, context))
o = torch.stack(o, 0)
o = self.linear(o.view(-1, h.size(1)))
return F.log_softmax(o).view(x_seq.size(0), -1, o.size(1)), h, cThe following G2P model is a combination of the above encoder and decoder into an end-to-end setting. We also use beam search to find the best converted phoneme sequence. To learn more about beam search, the following clip is helpful. In the implementation of beam search, we deal with one sequence at a time (try to find the phoneme sequence ending with token eos). So we have to make sure batch_size == 1.
class G2P(nn.Module):
def __init__(self, config):
super(G2P, self).__init__()
self.encoder = Encoder(config.g_size, config.d_embed,
config.d_hidden)
self.decoder = Decoder(config.p_size, config.d_embed,
config.d_hidden)
self.config = config
def forward(self, g_seq, p_seq=None):
o, h, c = self.encoder(g_seq, self.config.cuda)
context = o.t() if self.config.attention else None
if p_seq is not None: # not generate
return self.decoder(p_seq, h, c, context)
else:
assert g_seq.size(1) == 1 # make sure batch_size = 1
return self._generate(h, c, context)
def _generate(self, h, c, context):
beam = Beam(self.config.beam_size, cuda=self.config.cuda)
# Make a beam_size batch.
h = h.expand(beam.size, h.size(1))
c = c.expand(beam.size, c.size(1))
context = context.expand(beam.size, context.size(1), context.size(2))
for i in range(self.config.max_len): # max_len = 20
x = beam.get_current_state()
o, h, c = self.decoder(Variable(x.unsqueeze(0)), h, c, context)
if beam.advance(o.data.squeeze(0)):
break
h.data.copy_(h.data.index_select(0, beam.get_current_origin()))
c.data.copy_(c.data.index_select(0, beam.get_current_origin()))
tt = torch.cuda if self.config.cuda else torch
return Variable(tt.LongTensor(beam.get_hyp(0)))utils
The following class is the implementation of Beam search. Note that the special tokens pad, bos, eos have to match the corresponding tokens in phoneme dictionary.
# Based on https://github.com/MaximumEntropy/Seq2Seq-PyTorch/
class Beam(object):
"""Ordered beam of candidate outputs."""
def __init__(self, size, pad=1, bos=2, eos=3, cuda=False):
"""Initialize params."""
self.size = size
self.done = False
self.pad = pad
self.bos = bos
self.eos = eos
self.tt = torch.cuda if cuda else torch
# The score for each translation on the beam.
self.scores = self.tt.FloatTensor(size).zero_()
# The backpointers at each time-step.
self.prevKs = []
# The outputs at each time-step.
self.nextYs = [self.tt.LongTensor(size).fill_(self.pad)]
self.nextYs[0][0] = self.bos
# Get the outputs for the current timestep.
def get_current_state(self):
"""Get state of beam."""
return self.nextYs[-1]
# Get the backpointers for the current timestep.
def get_current_origin(self):
"""Get the backpointer to the beam at this step."""
return self.prevKs[-1]
def advance(self, workd_lk):
"""Advance the beam."""
num_words = workd_lk.size(1)
# Sum the previous scores.
if len(self.prevKs) > 0:
beam_lk = workd_lk + self.scores.unsqueeze(1).expand_as(workd_lk)
else:
beam_lk = workd_lk[0]
flat_beam_lk = beam_lk.view(-1)
bestScores, bestScoresId = flat_beam_lk.topk(self.size, 0,
True, True)
self.scores = bestScores
# bestScoresId is flattened beam x word array, so calculate which
# word and beam each score came from
prev_k = bestScoresId / num_words
self.prevKs.append(prev_k)
self.nextYs.append(bestScoresId - prev_k * num_words)
# End condition is when top-of-beam is EOS.
if self.nextYs[-1][0] == self.eos:
self.done = True
return self.done
def get_hyp(self, k):
"""Get hypotheses."""
hyp = []
# print(len(self.prevKs), len(self.nextYs), len(self.attn))
for j in range(len(self.prevKs) - 1, -1, -1):
hyp.append(self.nextYs[j + 1][k])
k = self.prevKs[j][k]
return hyp[::-1]Levenshtein distance is used to compute phoneme-error-rate (PER) for phoneme sequences (similar to word-error-rate for word sequences). In the paper, there is another metric named word-error-rate, which is obtained by calculating the number of wrong predictions. For example, the phoneme sequence “S W AY1 G ER0 D” is a wrong prediction for the word “sweigard” (real phoneme sequence is “S W EY1 G ER0 D”). Please not to be confused between these two metrics which have the same name.
# Based on https://github.com/SeanNaren/deepspeech.pytorch/blob/master/decoder.py.
import Levenshtein # https://github.com/ztane/python-Levenshtein/
def phoneme_error_rate(p_seq1, p_seq2):
p_vocab = set(p_seq1 + p_seq2)
p2c = dict(zip(p_vocab, range(len(p_vocab))))
c_seq1 = [chr(p2c[p]) for p in p_seq1]
c_seq2 = [chr(p2c[p]) for p in p_seq2]
return Levenshtein.distance(''.join(c_seq1),
''.join(c_seq2)) / len(c_seq2)The following function helps to adjust learning rate for optimizer. Learning rate will be decayed if we do not see any improvement of the loss after args.n_bad_loss iterations.
def adjust_learning_rate(optimizer, lr_decay):
for param_group in optimizer.param_groups:
param_group['lr'] *= lr_decaytrain
The following functions will be used to train model, validate model (using early stopping). Then we apply the final model for test data to get WER and PER (using test function). Finally, the show function will display a few examples for us.
def train(config, train_iter, model, criterion, optimizer, epoch):
global iteration, n_total, train_loss, n_bad_loss
global init, best_val_loss, stop
print("=> EPOCH {}".format(epoch))
train_iter.init_epoch()
for batch in train_iter:
iteration += 1
model.train()
output, _, __ = model(batch.grapheme, batch.phoneme[:-1].detach())
target = batch.phoneme[1:]
loss = criterion(output.view(output.size(0) * output.size(1), -1),
target.view(target.size(0) * target.size(1)))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm(model.parameters(), config.clip, 'inf')
optimizer.step()
n_total += batch.batch_size
train_loss += loss.data[0] * batch.batch_size
if iteration % config.log_every == 0:
train_loss /= n_total
val_loss = validate(val_iter, model, criterion)
print(" % Time: {:5.0f} | Iteration: {:5} | Batch: {:4}/{}"
" | Train loss: {:.4f} | Val loss: {:.4f}"
.format(time.time()-init, iteration, train_iter.iterations,
len(train_iter), train_loss, val_loss))
# test for val_loss improvement
n_total = train_loss = 0
if val_loss < best_val_loss:
best_val_loss = val_loss
n_bad_loss = 0
torch.save(model.state_dict(), config.best_model)
else:
n_bad_loss += 1
if n_bad_loss == config.n_bad_loss:
best_val_loss = val_loss
n_bad_loss = 0
adjust_learning_rate(optimizer, config.lr_decay)
new_lr = optimizer.param_groups[0]['lr']
print("=> Adjust learning rate to: {}".format(new_lr))
if new_lr < config.lr_min:
stop = True
break def validate(val_iter, model, criterion):
model.eval()
val_loss = 0
val_iter.init_epoch()
for batch in val_iter:
output, _, __ = model(batch.grapheme, batch.phoneme[:-1])
target = batch.phoneme[1:]
loss = criterion(output.squeeze(1), target.squeeze(1))
val_loss += loss.data[0] * batch.batch_size
return val_loss / len(val_iter.dataset)def test(test_iter, model, criterion):
model.eval()
test_iter.init_epoch()
test_per = test_wer = 0
for batch in test_iter:
output = model(batch.grapheme).data.tolist()
target = batch.phoneme[1:].squeeze(1).data.tolist()
# calculate per, wer here
per = phoneme_error_rate(output, target)
wer = int(output != target)
test_per += per # batch_size = 1
test_wer += wer
test_per = test_per / len(test_iter.dataset) * 100
test_wer = test_wer / len(test_iter.dataset) * 100
print("Phoneme error rate (PER): {:.2f}\nWord error rate (WER): {:.2f}"
.format(test_per, test_wer))def show(batch, model):
assert batch.batch_size == 1
g_field = batch.dataset.fields['grapheme']
p_field = batch.dataset.fields['phoneme']
prediction = model(batch.grapheme).data.tolist()[:-1]
grapheme = batch.grapheme.squeeze(1).data.tolist()[1:][::-1]
phoneme = batch.phoneme.squeeze(1).data.tolist()[1:-1]
print("> {}\n= {}\n< {}\n".format(
''.join([g_field.vocab.itos[g] for g in grapheme]),
' '.join([p_field.vocab.itos[p] for p in phoneme]),
' '.join([p_field.vocab.itos[p] for p in prediction])))prepare
Now, we move to the exciting part. We will create a class CMUDict based on data.Dataset from torchtext. It is recommended to read the document to understand how the Dataset works. The splits function helps us divide data into three datasets: 17/20 for training, 1/20 for validating, 2/20 for reporting final results.
The class CMUDict contains all pairs of a grapheme sequence and the corresponding phoneme sequence. Each line of the raw cmudict.dict file has the form “aachener AA1 K AH0 N ER0”. We first split it into sequences aachener and AA1 K AH0 N ER0. Each of them is a sequence of data belongs to a Field (for example, a sentence is a sequence of words and word is the Field of sentences). How to tokenize these sequences is implemented in the tokenize parameters of the definition of grapheme field and phoneme field. We also add init token and end-of-sequence token as in the original paper.
g_field = data.Field(init_token='<s>',
tokenize=(lambda x: list(x.split('(')[0])[::-1]))
p_field = data.Field(init_token='<os>', eos_token='</os>',
tokenize=(lambda x: x.split('#')[0].split()))class CMUDict(data.Dataset):
def __init__(self, data_lines, g_field, p_field):
fields = [('grapheme', g_field), ('phoneme', p_field)]
examples = [] # maybe ignore '...-1' grapheme
for line in data_lines:
grapheme, phoneme = line.split(maxsplit=1)
examples.append(data.Example.fromlist([grapheme, phoneme],
fields))
self.sort_key = lambda x: len(x.grapheme)
super(CMUDict, self).__init__(examples, fields)
@classmethod
def splits(cls, path, g_field, p_field, seed=None):
import random
if seed is not None:
random.seed(seed)
with open(path) as f:
lines = f.readlines()
random.shuffle(lines)
train_lines, val_lines, test_lines = [], [], []
for i, line in enumerate(lines):
if i % 20 == 0:
val_lines.append(line)
elif i % 20 < 3:
test_lines.append(line)
else:
train_lines.append(line)
train_data = cls(train_lines, g_field, p_field)
val_data = cls(val_lines, g_field, p_field)
test_data = cls(test_lines, g_field, p_field)
return (train_data, val_data, test_data)filepath = os.path.join(args.data_path, 'cmudict.dict')
train_data, val_data, test_data = CMUDict.splits(filepath, g_field, p_field,
args.seed)To make the dictionaries for grapheme field and phoneme field, we use the function build_vocab. Read its definition to get more information.
g_field.build_vocab(train_data, val_data, test_data)
p_field.build_vocab(train_data, val_data, test_data)Now, we will make Iterator from our datasets. These iterators will help us get data in batch. The BucketIterator will make the sequences in each batch have similar length while still preserves the randomness.
device = None if args.cuda else -1 # None is current gpu
train_iter = data.BucketIterator(train_data, batch_size=args.batch_size,
repeat=False, device=device)
val_iter = data.Iterator(val_data, batch_size=1,
train=False, sort=False, device=device)
test_iter = data.Iterator(test_data, batch_size=1,
train=False, shuffle=True, device=device)Now, it is time to create the model.
config = args
config.g_size = len(g_field.vocab)
config.p_size = len(p_field.vocab)
config.best_model = os.path.join(config.intermediate_path,
"best_model_adagrad_attn.pth")
model = G2P(config)
criterion = nn.NLLLoss()
if config.cuda:
model.cuda()
criterion.cuda()
optimizer = optim.Adagrad(model.parameters(), lr=config.lr) # use Adagradrun
We start to train our model. It will be stopped if there is no observation on the improvement of validation loss. It take around 10 minutes for each epoch (trained on GTX 1060).
if 1 == 1: # change to True to train
iteration = n_total = train_loss = n_bad_loss = 0
stop = False
best_val_loss = 10
init = time.time()
for epoch in range(1, config.epochs+1):
train(config, train_iter, model, criterion, optimizer, epoch)
if stop:
break=> EPOCH 1
% Time: 56 | Iteration: 100 | Batch: 100/1148 | Train loss: 1.3804 | Val loss: 0.8835
% Time: 111 | Iteration: 200 | Batch: 200/1148 | Train loss: 0.5339 | Val loss: 0.5970
% Time: 166 | Iteration: 300 | Batch: 300/1148 | Train loss: 0.4361 | Val loss: 0.5435
% Time: 220 | Iteration: 400 | Batch: 400/1148 | Train loss: 0.3836 | Val loss: 0.4764
% Time: 275 | Iteration: 500 | Batch: 500/1148 | Train loss: 0.3578 | Val loss: 0.4410
% Time: 331 | Iteration: 600 | Batch: 600/1148 | Train loss: 0.3315 | Val loss: 0.4162
% Time: 387 | Iteration: 700 | Batch: 700/1148 | Train loss: 0.3230 | Val loss: 0.4009
% Time: 442 | Iteration: 800 | Batch: 800/1148 | Train loss: 0.3186 | Val loss: 0.4340
% Time: 498 | Iteration: 900 | Batch: 900/1148 | Train loss: 0.2955 | Val loss: 0.3801
% Time: 554 | Iteration: 1000 | Batch: 1000/1148 | Train loss: 0.2954 | Val loss: 0.3637
% Time: 609 | Iteration: 1100 | Batch: 1100/1148 | Train loss: 0.2801 | Val loss: 0.3642
=> EPOCH 2
% Time: 664 | Iteration: 1200 | Batch: 52/1148 | Train loss: 0.2815 | Val loss: 0.3511
% Time: 720 | Iteration: 1300 | Batch: 152/1148 | Train loss: 0.2525 | Val loss: 0.3467
% Time: 776 | Iteration: 1400 | Batch: 252/1148 | Train loss: 0.2519 | Val loss: 0.3396
% Time: 831 | Iteration: 1500 | Batch: 352/1148 | Train loss: 0.2548 | Val loss: 0.3322
% Time: 887 | Iteration: 1600 | Batch: 452/1148 | Train loss: 0.2522 | Val loss: 0.3294
% Time: 944 | Iteration: 1700 | Batch: 552/1148 | Train loss: 0.2457 | Val loss: 0.3278
% Time: 1000 | Iteration: 1800 | Batch: 652/1148 | Train loss: 0.2460 | Val loss: 0.3224
% Time: 1055 | Iteration: 1900 | Batch: 752/1148 | Train loss: 0.2465 | Val loss: 0.3175
% Time: 1112 | Iteration: 2000 | Batch: 852/1148 | Train loss: 0.2321 | Val loss: 0.3157
% Time: 1167 | Iteration: 2100 | Batch: 952/1148 | Train loss: 0.2480 | Val loss: 0.3141
% Time: 1222 | Iteration: 2200 | Batch: 1052/1148 | Train loss: 0.2309 | Val loss: 0.3120
=> EPOCH 3
% Time: 1278 | Iteration: 2300 | Batch: 4/1148 | Train loss: 0.2322 | Val loss: 0.3077
% Time: 1334 | Iteration: 2400 | Batch: 104/1148 | Train loss: 0.2225 | Val loss: 0.3069
% Time: 1390 | Iteration: 2500 | Batch: 204/1148 | Train loss: 0.2131 | Val loss: 0.3050
% Time: 1445 | Iteration: 2600 | Batch: 304/1148 | Train loss: 0.2201 | Val loss: 0.3006
% Time: 1502 | Iteration: 2700 | Batch: 404/1148 | Train loss: 0.2241 | Val loss: 0.3019
% Time: 1557 | Iteration: 2800 | Batch: 504/1148 | Train loss: 0.2138 | Val loss: 0.2980
% Time: 1613 | Iteration: 2900 | Batch: 604/1148 | Train loss: 0.2181 | Val loss: 0.2967
% Time: 1670 | Iteration: 3000 | Batch: 704/1148 | Train loss: 0.2160 | Val loss: 0.2951
% Time: 1726 | Iteration: 3100 | Batch: 804/1148 | Train loss: 0.2170 | Val loss: 0.2919
% Time: 1782 | Iteration: 3200 | Batch: 904/1148 | Train loss: 0.2156 | Val loss: 0.2915
% Time: 1837 | Iteration: 3300 | Batch: 1004/1148 | Train loss: 0.2158 | Val loss: 0.2899
% Time: 1893 | Iteration: 3400 | Batch: 1104/1148 | Train loss: 0.2117 | Val loss: 0.2880
=> EPOCH 4
% Time: 1948 | Iteration: 3500 | Batch: 56/1148 | Train loss: 0.2026 | Val loss: 0.2869
% Time: 2003 | Iteration: 3600 | Batch: 156/1148 | Train loss: 0.2011 | Val loss: 0.2839
% Time: 2060 | Iteration: 3700 | Batch: 256/1148 | Train loss: 0.1960 | Val loss: 0.2856
% Time: 2117 | Iteration: 3800 | Batch: 356/1148 | Train loss: 0.2036 | Val loss: 0.2848
% Time: 2173 | Iteration: 3900 | Batch: 456/1148 | Train loss: 0.1982 | Val loss: 0.2823
% Time: 2228 | Iteration: 4000 | Batch: 556/1148 | Train loss: 0.1970 | Val loss: 0.2820
% Time: 2283 | Iteration: 4100 | Batch: 656/1148 | Train loss: 0.2014 | Val loss: 0.2796
% Time: 2338 | Iteration: 4200 | Batch: 756/1148 | Train loss: 0.2015 | Val loss: 0.2801
% Time: 2393 | Iteration: 4300 | Batch: 856/1148 | Train loss: 0.1924 | Val loss: 0.2782
% Time: 2450 | Iteration: 4400 | Batch: 956/1148 | Train loss: 0.1991 | Val loss: 0.2777
% Time: 2506 | Iteration: 4500 | Batch: 1056/1148 | Train loss: 0.1971 | Val loss: 0.2774
=> EPOCH 5
% Time: 2563 | Iteration: 4600 | Batch: 8/1148 | Train loss: 0.1975 | Val loss: 0.2764
% Time: 2619 | Iteration: 4700 | Batch: 108/1148 | Train loss: 0.1846 | Val loss: 0.2752
% Time: 2675 | Iteration: 4800 | Batch: 208/1148 | Train loss: 0.1878 | Val loss: 0.2741
% Time: 2731 | Iteration: 4900 | Batch: 308/1148 | Train loss: 0.1843 | Val loss: 0.2742
% Time: 2788 | Iteration: 5000 | Batch: 408/1148 | Train loss: 0.1832 | Val loss: 0.2733
% Time: 2843 | Iteration: 5100 | Batch: 508/1148 | Train loss: 0.1898 | Val loss: 0.2740
% Time: 2898 | Iteration: 5200 | Batch: 608/1148 | Train loss: 0.1856 | Val loss: 0.2713
% Time: 2955 | Iteration: 5300 | Batch: 708/1148 | Train loss: 0.1872 | Val loss: 0.2704
% Time: 3011 | Iteration: 5400 | Batch: 808/1148 | Train loss: 0.1889 | Val loss: 0.2715
% Time: 3068 | Iteration: 5500 | Batch: 908/1148 | Train loss: 0.1861 | Val loss: 0.2703
% Time: 3123 | Iteration: 5600 | Batch: 1008/1148 | Train loss: 0.1837 | Val loss: 0.2700
% Time: 3178 | Iteration: 5700 | Batch: 1108/1148 | Train loss: 0.1873 | Val loss: 0.2696
=> EPOCH 6
% Time: 3233 | Iteration: 5800 | Batch: 60/1148 | Train loss: 0.1859 | Val loss: 0.2662
% Time: 3290 | Iteration: 5900 | Batch: 160/1148 | Train loss: 0.1745 | Val loss: 0.2677
% Time: 3346 | Iteration: 6000 | Batch: 260/1148 | Train loss: 0.1755 | Val loss: 0.2658
% Time: 3403 | Iteration: 6100 | Batch: 360/1148 | Train loss: 0.1725 | Val loss: 0.2678
% Time: 3458 | Iteration: 6200 | Batch: 460/1148 | Train loss: 0.1791 | Val loss: 0.2659
% Time: 3514 | Iteration: 6300 | Batch: 560/1148 | Train loss: 0.1762 | Val loss: 0.2655
% Time: 3570 | Iteration: 6400 | Batch: 660/1148 | Train loss: 0.1745 | Val loss: 0.2657
% Time: 3626 | Iteration: 6500 | Batch: 760/1148 | Train loss: 0.1739 | Val loss: 0.2637
% Time: 3682 | Iteration: 6600 | Batch: 860/1148 | Train loss: 0.1755 | Val loss: 0.2646
% Time: 3738 | Iteration: 6700 | Batch: 960/1148 | Train loss: 0.1766 | Val loss: 0.2641
% Time: 3794 | Iteration: 6800 | Batch: 1060/1148 | Train loss: 0.1730 | Val loss: 0.2637
=> EPOCH 7
% Time: 3851 | Iteration: 6900 | Batch: 12/1148 | Train loss: 0.1757 | Val loss: 0.2621
% Time: 3906 | Iteration: 7000 | Batch: 112/1148 | Train loss: 0.1631 | Val loss: 0.2614
% Time: 3961 | Iteration: 7100 | Batch: 212/1148 | Train loss: 0.1665 | Val loss: 0.2641
% Time: 4017 | Iteration: 7200 | Batch: 312/1148 | Train loss: 0.1683 | Val loss: 0.2616
% Time: 4073 | Iteration: 7300 | Batch: 412/1148 | Train loss: 0.1698 | Val loss: 0.2618
% Time: 4128 | Iteration: 7400 | Batch: 512/1148 | Train loss: 0.1679 | Val loss: 0.2605
% Time: 4185 | Iteration: 7500 | Batch: 612/1148 | Train loss: 0.1689 | Val loss: 0.2594
% Time: 4240 | Iteration: 7600 | Batch: 712/1148 | Train loss: 0.1673 | Val loss: 0.2597
% Time: 4296 | Iteration: 7700 | Batch: 812/1148 | Train loss: 0.1706 | Val loss: 0.2591
% Time: 4352 | Iteration: 7800 | Batch: 912/1148 | Train loss: 0.1658 | Val loss: 0.2585
% Time: 4409 | Iteration: 7900 | Batch: 1012/1148 | Train loss: 0.1705 | Val loss: 0.2577
% Time: 4465 | Iteration: 8000 | Batch: 1112/1148 | Train loss: 0.1669 | Val loss: 0.2585
=> EPOCH 8
% Time: 4521 | Iteration: 8100 | Batch: 64/1148 | Train loss: 0.1577 | Val loss: 0.2581
% Time: 4576 | Iteration: 8200 | Batch: 164/1148 | Train loss: 0.1636 | Val loss: 0.2555
% Time: 4633 | Iteration: 8300 | Batch: 264/1148 | Train loss: 0.1569 | Val loss: 0.2568
% Time: 4689 | Iteration: 8400 | Batch: 364/1148 | Train loss: 0.1599 | Val loss: 0.2560
% Time: 4745 | Iteration: 8500 | Batch: 464/1148 | Train loss: 0.1593 | Val loss: 0.2570
% Time: 4802 | Iteration: 8600 | Batch: 564/1148 | Train loss: 0.1607 | Val loss: 0.2555
% Time: 4858 | Iteration: 8700 | Batch: 664/1148 | Train loss: 0.1546 | Val loss: 0.2553
% Time: 4915 | Iteration: 8800 | Batch: 764/1148 | Train loss: 0.1636 | Val loss: 0.2565
% Time: 4971 | Iteration: 8900 | Batch: 864/1148 | Train loss: 0.1616 | Val loss: 0.2537
% Time: 5027 | Iteration: 9000 | Batch: 964/1148 | Train loss: 0.1614 | Val loss: 0.2550
% Time: 5083 | Iteration: 9100 | Batch: 1064/1148 | Train loss: 0.1591 | Val loss: 0.2559
=> EPOCH 9
% Time: 5140 | Iteration: 9200 | Batch: 16/1148 | Train loss: 0.1624 | Val loss: 0.2565
% Time: 5197 | Iteration: 9300 | Batch: 116/1148 | Train loss: 0.1513 | Val loss: 0.2552
% Time: 5253 | Iteration: 9400 | Batch: 216/1148 | Train loss: 0.1559 | Val loss: 0.2545
=> Adjust learning rate to: 0.0035
% Time: 5309 | Iteration: 9500 | Batch: 316/1148 | Train loss: 0.1471 | Val loss: 0.2519
% Time: 5366 | Iteration: 9600 | Batch: 416/1148 | Train loss: 0.1512 | Val loss: 0.2510
% Time: 5421 | Iteration: 9700 | Batch: 516/1148 | Train loss: 0.1508 | Val loss: 0.2504
% Time: 5477 | Iteration: 9800 | Batch: 616/1148 | Train loss: 0.1493 | Val loss: 0.2512
% Time: 5532 | Iteration: 9900 | Batch: 716/1148 | Train loss: 0.1542 | Val loss: 0.2500
% Time: 5588 | Iteration: 10000 | Batch: 816/1148 | Train loss: 0.1480 | Val loss: 0.2498
% Time: 5644 | Iteration: 10100 | Batch: 916/1148 | Train loss: 0.1494 | Val loss: 0.2494
% Time: 5700 | Iteration: 10200 | Batch: 1016/1148 | Train loss: 0.1483 | Val loss: 0.2490
% Time: 5755 | Iteration: 10300 | Batch: 1116/1148 | Train loss: 0.1499 | Val loss: 0.2484
=> EPOCH 10
% Time: 5811 | Iteration: 10400 | Batch: 68/1148 | Train loss: 0.1406 | Val loss: 0.2492
% Time: 5866 | Iteration: 10500 | Batch: 168/1148 | Train loss: 0.1467 | Val loss: 0.2494
% Time: 5922 | Iteration: 10600 | Batch: 268/1148 | Train loss: 0.1433 | Val loss: 0.2495
% Time: 5978 | Iteration: 10700 | Batch: 368/1148 | Train loss: 0.1454 | Val loss: 0.2490
% Time: 6033 | Iteration: 10800 | Batch: 468/1148 | Train loss: 0.1428 | Val loss: 0.2494
=> Adjust learning rate to: 0.00175
% Time: 6089 | Iteration: 10900 | Batch: 568/1148 | Train loss: 0.1447 | Val loss: 0.2482
% Time: 6144 | Iteration: 11000 | Batch: 668/1148 | Train loss: 0.1493 | Val loss: 0.2479
% Time: 6200 | Iteration: 11100 | Batch: 768/1148 | Train loss: 0.1445 | Val loss: 0.2479
% Time: 6257 | Iteration: 11200 | Batch: 868/1148 | Train loss: 0.1415 | Val loss: 0.2476
% Time: 6312 | Iteration: 11300 | Batch: 968/1148 | Train loss: 0.1436 | Val loss: 0.2469
% Time: 6368 | Iteration: 11400 | Batch: 1068/1148 | Train loss: 0.1423 | Val loss: 0.2473
=> EPOCH 11
% Time: 6423 | Iteration: 11500 | Batch: 20/1148 | Train loss: 0.1487 | Val loss: 0.2474
% Time: 6478 | Iteration: 11600 | Batch: 120/1148 | Train loss: 0.1435 | Val loss: 0.2478
% Time: 6535 | Iteration: 11700 | Batch: 220/1148 | Train loss: 0.1402 | Val loss: 0.2475
% Time: 6591 | Iteration: 11800 | Batch: 320/1148 | Train loss: 0.1378 | Val loss: 0.2476
=> Adjust learning rate to: 0.000875
% Time: 6647 | Iteration: 11900 | Batch: 420/1148 | Train loss: 0.1451 | Val loss: 0.2474
% Time: 6702 | Iteration: 12000 | Batch: 520/1148 | Train loss: 0.1400 | Val loss: 0.2475
% Time: 6759 | Iteration: 12100 | Batch: 620/1148 | Train loss: 0.1377 | Val loss: 0.2473
% Time: 6814 | Iteration: 12200 | Batch: 720/1148 | Train loss: 0.1383 | Val loss: 0.2474
% Time: 6871 | Iteration: 12300 | Batch: 820/1148 | Train loss: 0.1442 | Val loss: 0.2471
% Time: 6927 | Iteration: 12400 | Batch: 920/1148 | Train loss: 0.1383 | Val loss: 0.2471
% Time: 6983 | Iteration: 12500 | Batch: 1020/1148 | Train loss: 0.1407 | Val loss: 0.2472
% Time: 7040 | Iteration: 12600 | Batch: 1120/1148 | Train loss: 0.1398 | Val loss: 0.2469
=> EPOCH 12
% Time: 7095 | Iteration: 12700 | Batch: 72/1148 | Train loss: 0.1427 | Val loss: 0.2470
% Time: 7151 | Iteration: 12800 | Batch: 172/1148 | Train loss: 0.1362 | Val loss: 0.2473
% Time: 7208 | Iteration: 12900 | Batch: 272/1148 | Train loss: 0.1395 | Val loss: 0.2473
% Time: 7264 | Iteration: 13000 | Batch: 372/1148 | Train loss: 0.1396 | Val loss: 0.2474
% Time: 7320 | Iteration: 13100 | Batch: 472/1148 | Train loss: 0.1377 | Val loss: 0.2472
=> Adjust learning rate to: 0.0004375
% Time: 7376 | Iteration: 13200 | Batch: 572/1148 | Train loss: 0.1377 | Val loss: 0.2472
% Time: 7432 | Iteration: 13300 | Batch: 672/1148 | Train loss: 0.1415 | Val loss: 0.2470
% Time: 7488 | Iteration: 13400 | Batch: 772/1148 | Train loss: 0.1387 | Val loss: 0.2469
% Time: 7544 | Iteration: 13500 | Batch: 872/1148 | Train loss: 0.1402 | Val loss: 0.2470
% Time: 7600 | Iteration: 13600 | Batch: 972/1148 | Train loss: 0.1397 | Val loss: 0.2469
% Time: 7655 | Iteration: 13700 | Batch: 1072/1148 | Train loss: 0.1370 | Val loss: 0.2469
=> EPOCH 13
% Time: 7712 | Iteration: 13800 | Batch: 24/1148 | Train loss: 0.1405 | Val loss: 0.2469
% Time: 7769 | Iteration: 13900 | Batch: 124/1148 | Train loss: 0.1368 | Val loss: 0.2470
% Time: 7824 | Iteration: 14000 | Batch: 224/1148 | Train loss: 0.1343 | Val loss: 0.2470
% Time: 7879 | Iteration: 14100 | Batch: 324/1148 | Train loss: 0.1376 | Val loss: 0.2471
% Time: 7934 | Iteration: 14200 | Batch: 424/1148 | Train loss: 0.1400 | Val loss: 0.2472
=> Adjust learning rate to: 0.00021875
% Time: 7990 | Iteration: 14300 | Batch: 524/1148 | Train loss: 0.1347 | Val loss: 0.2471
% Time: 8047 | Iteration: 14400 | Batch: 624/1148 | Train loss: 0.1405 | Val loss: 0.2471
% Time: 8103 | Iteration: 14500 | Batch: 724/1148 | Train loss: 0.1392 | Val loss: 0.2471
% Time: 8159 | Iteration: 14600 | Batch: 824/1148 | Train loss: 0.1359 | Val loss: 0.2470
% Time: 8214 | Iteration: 14700 | Batch: 924/1148 | Train loss: 0.1396 | Val loss: 0.2470
% Time: 8270 | Iteration: 14800 | Batch: 1024/1148 | Train loss: 0.1365 | Val loss: 0.2471
% Time: 8327 | Iteration: 14900 | Batch: 1124/1148 | Train loss: 0.1355 | Val loss: 0.2470
=> EPOCH 14
% Time: 8383 | Iteration: 15000 | Batch: 76/1148 | Train loss: 0.1354 | Val loss: 0.2470
% Time: 8439 | Iteration: 15100 | Batch: 176/1148 | Train loss: 0.1397 | Val loss: 0.2470
% Time: 8495 | Iteration: 15200 | Batch: 276/1148 | Train loss: 0.1350 | Val loss: 0.2471
% Time: 8551 | Iteration: 15300 | Batch: 376/1148 | Train loss: 0.1393 | Val loss: 0.2471
% Time: 8607 | Iteration: 15400 | Batch: 476/1148 | Train loss: 0.1378 | Val loss: 0.2470
=> Adjust learning rate to: 0.000109375
% Time: 8663 | Iteration: 15500 | Batch: 576/1148 | Train loss: 0.1364 | Val loss: 0.2470
% Time: 8720 | Iteration: 15600 | Batch: 676/1148 | Train loss: 0.1372 | Val loss: 0.2470
% Time: 8776 | Iteration: 15700 | Batch: 776/1148 | Train loss: 0.1346 | Val loss: 0.2470
% Time: 8832 | Iteration: 15800 | Batch: 876/1148 | Train loss: 0.1371 | Val loss: 0.2470
% Time: 8888 | Iteration: 15900 | Batch: 976/1148 | Train loss: 0.1360 | Val loss: 0.2470
% Time: 8944 | Iteration: 16000 | Batch: 1076/1148 | Train loss: 0.1378 | Val loss: 0.2470
=> EPOCH 15
% Time: 9001 | Iteration: 16100 | Batch: 28/1148 | Train loss: 0.1364 | Val loss: 0.2470
=> Adjust learning rate to: 5.46875e-05
% Time: 9057 | Iteration: 16200 | Batch: 128/1148 | Train loss: 0.1377 | Val loss: 0.2471
% Time: 9113 | Iteration: 16300 | Batch: 228/1148 | Train loss: 0.1374 | Val loss: 0.2471
% Time: 9170 | Iteration: 16400 | Batch: 328/1148 | Train loss: 0.1355 | Val loss: 0.2471
% Time: 9225 | Iteration: 16500 | Batch: 428/1148 | Train loss: 0.1350 | Val loss: 0.2471
% Time: 9281 | Iteration: 16600 | Batch: 528/1148 | Train loss: 0.1362 | Val loss: 0.2471
=> Adjust learning rate to: 2.734375e-05
% Time: 9337 | Iteration: 16700 | Batch: 628/1148 | Train loss: 0.1357 | Val loss: 0.2471
% Time: 9394 | Iteration: 16800 | Batch: 728/1148 | Train loss: 0.1392 | Val loss: 0.2471
% Time: 9450 | Iteration: 16900 | Batch: 828/1148 | Train loss: 0.1398 | Val loss: 0.2470
% Time: 9505 | Iteration: 17000 | Batch: 928/1148 | Train loss: 0.1384 | Val loss: 0.2470
% Time: 9561 | Iteration: 17100 | Batch: 1028/1148 | Train loss: 0.1374 | Val loss: 0.2470
% Time: 9618 | Iteration: 17200 | Batch: 1128/1148 | Train loss: 0.1394 | Val loss: 0.2470
=> EPOCH 16
% Time: 9674 | Iteration: 17300 | Batch: 80/1148 | Train loss: 0.1362 | Val loss: 0.2470
% Time: 9730 | Iteration: 17400 | Batch: 180/1148 | Train loss: 0.1383 | Val loss: 0.2470
% Time: 9786 | Iteration: 17500 | Batch: 280/1148 | Train loss: 0.1372 | Val loss: 0.2470
% Time: 9841 | Iteration: 17600 | Batch: 380/1148 | Train loss: 0.1346 | Val loss: 0.2470
=> Adjust learning rate to: 1.3671875e-05
% Time: 9897 | Iteration: 17700 | Batch: 480/1148 | Train loss: 0.1363 | Val loss: 0.2470
% Time: 9952 | Iteration: 17800 | Batch: 580/1148 | Train loss: 0.1385 | Val loss: 0.2470
% Time: 10008 | Iteration: 17900 | Batch: 680/1148 | Train loss: 0.1374 | Val loss: 0.2470
% Time: 10063 | Iteration: 18000 | Batch: 780/1148 | Train loss: 0.1365 | Val loss: 0.2470
% Time: 10118 | Iteration: 18100 | Batch: 880/1148 | Train loss: 0.1374 | Val loss: 0.2470
% Time: 10173 | Iteration: 18200 | Batch: 980/1148 | Train loss: 0.1366 | Val loss: 0.2470
% Time: 10230 | Iteration: 18300 | Batch: 1080/1148 | Train loss: 0.1376 | Val loss: 0.2470
=> EPOCH 17
% Time: 10287 | Iteration: 18400 | Batch: 32/1148 | Train loss: 0.1369 | Val loss: 0.2470
% Time: 10343 | Iteration: 18500 | Batch: 132/1148 | Train loss: 0.1371 | Val loss: 0.2470
% Time: 10398 | Iteration: 18600 | Batch: 232/1148 | Train loss: 0.1358 | Val loss: 0.2470
=> Adjust learning rate to: 6.8359375e-06test
We also want to report WER and PER. In this notebook, we use attention. Setting args.attention to False to disable it, which will improve the results.
model.load_state_dict(torch.load(config.best_model))
test(test_iter, model, criterion)Phoneme error rate (PER): 9.81
Word error rate (WER): 40.66Now we display 10 examples. The first line is the word, the second line is its ‘true’ phoneme, and the third line is our prediction.
test_iter.init_epoch()
for i, batch in enumerate(test_iter):
show(batch, model)
if i == 10:
break> pacheco
= P AH0 CH EH1 K OW0
< P AH0 CH EH1 K OW0
> affable
= AE1 F AH0 B AH0 L
< AE1 F AH0 B AH0 L
> mauriello
= M AO2 R IY0 EH1 L OW0
< M AO0 R IY0 EH1 L OW0
> schadler
= SH EY1 D AH0 L ER0
< SH AE1 D L ER0
> chandon
= CH AE1 N D IH0 N
< CH AE1 N D AH0 N
> sines
= S AY1 N Z
< S AY1 N Z
> nostrums
= N AA1 S T R AH0 M Z
< N AA1 S T R AH0 M Z
> guandong's
= G W AA1 N D OW2 NG Z
< G W AA1 N D AO1 NG Z
> pry
= P R AY1
< P R AY1
> biddie
= B IH1 D IY0
< B IH1 D IY0
> manes
= M EY1 N Z
< M EY1 N Z
As you can see, the result is quite good. Happy learning!
acknowledgement
This tutorial is done under my study with Hoang Le and Hoang Nguyen. Thank you very much for your help!